实验目的
1、网络爬虫的基本原理与规范。
2、掌握使用 Requests 库获取静态网页信息。
3、掌握使用 BeautifulSoup4 库解析网页信息。
4、掌握正则表达式的基本用法。
实验内容
题目 中国大学排名定向爬虫
(1) 查看 https://www.shanghairanking.cn/rankings/bcur/2020 网页中关于各大学排名的信息组织(F12 快捷键查阅 html 代码)
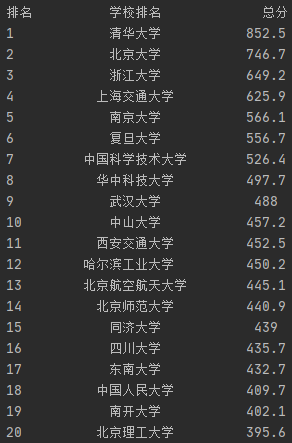
(2)使用 requests、beautifulsoup4 或 re 库抓取并解析排名,输出各大学的排名信息,如下图所示。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUniviList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].text,tds[1].text,tds[4].text])
def printUnivList(ulist,num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校排名","总分",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0].strip(),u[1].strip(),u[2].strip(),chr(12288)))
def main():
uinfo = []
url = 'https://www.shanghairanking.cn/rankings/bcur/2020'
html = getHTMLText(url)
fillUniviList(uinfo,html)
printUnivList(uinfo,20)
main()
|


